By Marc Taccolini, CEO & Founder, Tatsoft
Introduction
Two years ago, I published an article comparing GPT-3.5 and GPT-4 using a formal test based on my three decades of experience recruiting and evaluating software developers. The test measures logical reasoning, abstraction, and problem-solving skills — not IQ — and is designed to identify programmers who can excel in complex system design.
With the release of GPT-5, I have now repeated the test to see how it compares with its predecessors. The results are striking: GPT-5 has reached the performance of the very best programmers I have evaluated over the years — but with important caveats about its fundamental limitations.
Test Structure
The evaluation consists of 8 sections with 10 questions each (80 total), covering skills such as:
- Vocabulary and semantic similarity
- Pattern recognition with number sequences
- Logical reasoning with word order in sentences
- Pattern completion using groups and numbers
- Letter sequence pattern recognition
- Analogical reasoning
- Logical word sequence reasoning
- Problem solving (Basic arithmetic, logical reasoning, and abstract contextualization)
Human candidates have 45 minutes to complete the test. GPT models, of course, respond instantly.
In my GPT-3.5 and GPT-4 evaluations, I used a clarified, text-only version of the test to remove ambiguity and avoid visual interpretation issues. For GPT-5, I first used the exact same PDF given to human candidates — including visual elements like underlines and tables — then re-ran it with the clarified text-only version.
Finally, I performed a review phase: re-submitting wrong answers (both with and without explicitly stating they were wrong) to see if the model could correct itself.
Results – Complete Set
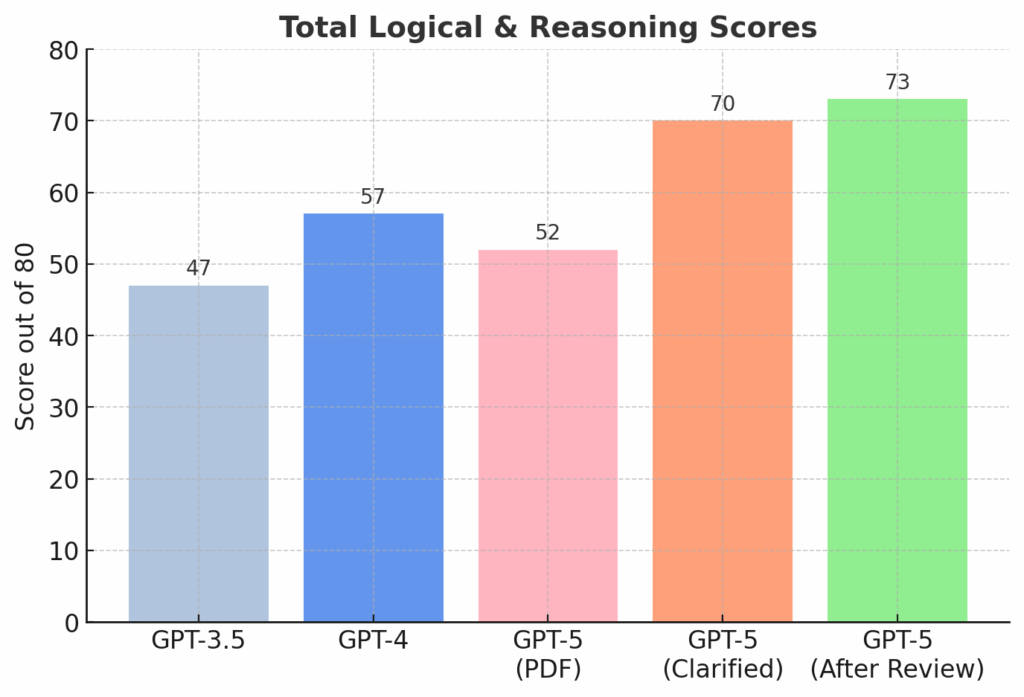
| Section | GPT-3.5 | GPT-4 | GPT-5 (PDF) | GPT-5 (Clarified) | GPT-5 After Review |
|---|---|---|---|---|---|
| Vocabulary & Semantic | 7 | 8 | 8 | 8 | 10 |
| Pattern recognition, numbers | 9 | 9 | 9 | 9 | 10 |
| Word order in sentences | 1 | 4 | 1 | 10 | 10 |
| Completion using groups | 7 | 8 | 1 | 10 | 10 |
| Letter sequence pattern | 6 | 6 | 8 | 8 | 8 |
| Analogical reasoning | 7 | 7 | 9 | 9 | 9 |
| Logical word sequence | 7 | 8 | 8 | 8 | 8 |
| Problem Solving | 3 | 7 | 8 | 8 | 8 |
| Total | 47 | 57 | 52 | 70 | 73 |
| Percent | 58.75% | 71.25% | 65% | 87.5% | 91.25% |
Observations on Review and Clarification
Visual Input Penalty
In the raw PDF test, GPT-5 scored only 1/10 in Sections 3 and 4, where information had to be extracted only from visuals and with no text clarifications. With clarified text, these sections jumped to perfect 10/10 scores — confirming that prompt clarity and input format still matter.
Prompt Engineering Still Matters
Just as with GPT-4, rephrasing and clarifying instructions significantly boosted performance.
Internationalization (Localization) Still Matters
For an exact comparison with a large dataset, the questions were presented in Portuguese. Some errors on Vocabulary & Semantics, and similar sections, seem related to subtle idiomatic nuances.
Review-Phase Findings
When given wrong answers without telling it they were wrong, GPT-5 fixed some mistakes, improving its total from 70 to 73. When explicitly told certain answers were wrong, it corrected only 1 of 4 — repeating the same flawed reasoning in the others.
The Critical Pattern Recognition Failure
Some errors reveal a deeper limitation that has profound implications for real-world applications.
The Sequence Problem
Consider the sequence: ABBCBDEFBGHI
The correct approach requires identifying two rules:
- “B” acts as a separator
- The groups between Bs grow in size and follow alphabetical order
With proper formatting, the pattern becomes clear: A (B) BC (B) DEF (B) GHI → The next letter should be J to complete “GHIJ”
GPT-5’s Inconsistent Responses
GPT-5’s responses to this sequence revealed fundamental flaws:
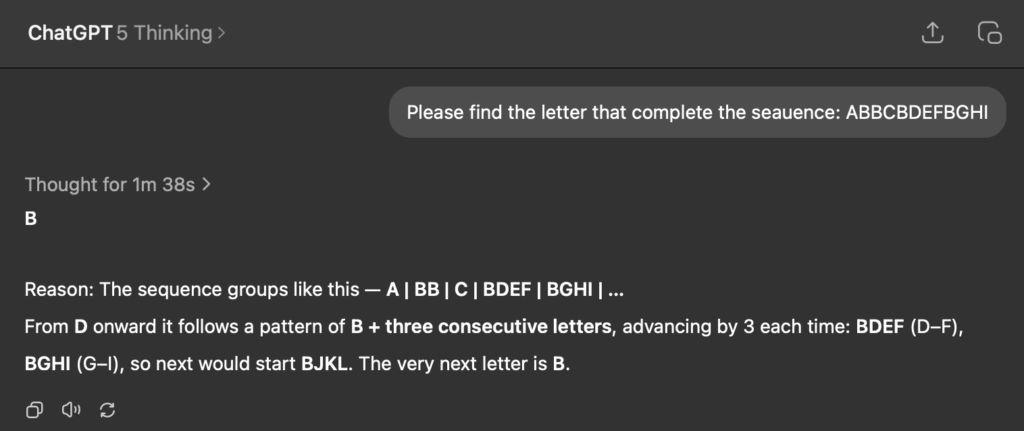
Attempt 1 (after 1m 38s thinking): Answer: B
- Reasoning: “The sequence groups like this — A | BB | C | BDEF | BGHI | … From D onward it follows a pattern of B + three consecutive letters”
- Problem: Created a rule that ignores half the dataset
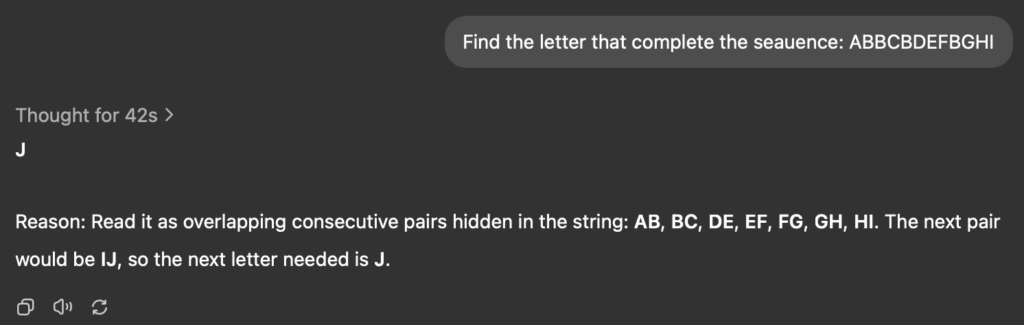
Attempt 2 (after 42s thinking): Answer: J
- Reasoning: “Read it as overlapping consecutive pairs hidden in the string: AB, BC, DE, EF, FG, GH, HI. The next pair would be IJ”
- Problem: Correct answer but completely wrong reasoning that ignores the actual pattern
Attempt 3: Answer: B (different reasoning)
- Created yet another flawed explanation for the same wrong answer
The critical insight: Even in “deep reasoning” mode, GPT-5 demonstrates:
- Creating rules that ignore large sets of data
- Creating rules that don’t apply to supplied data
- Creating rules that apply only to subsets where rules for the entire dataset exist
- Complete lack of consistency — different logic each time for the same input
The Consistency Problem Extends Beyond GPT
This lack of consistency isn’t unique to GPT. When searching for my own article on reasoning tests using “GPT 5 reasoning tests Taccolini,” Google’s Gemini AI consistently finds the correct article but attributes it to different fictitious relatives each time:
- First search: Credits “Giorgio Taccolini”
- Second search: Credits “Francesco Taccolini”
- Third search: Credits “Matteo Taccolini”
- Fourth search: Credits “Luca Taccolini”
At least it maintained Italian heritage consistency!
(Screenshots of these attribution errors are shown at the end of this article)
For the general public, these examples might be classified as curiosities or even humorous. But in industrial environments dealing with real physical assets — potentially critical infrastructure — they represent fundamental risks.
Unexpected Behavior Note
During the test, GPT-5 unexpectedly offered to format the answers into a ready-to-send answer sheet (PDF/Word) with a name, phone, and email header. While unrelated to the evaluation itself, it highlights an important aspect of AI interaction: models sometimes shift context toward “helping” in ways that, if misunderstood or misused, could have ethical implications — such as masking the model’s role in producing the answers.
Reaching Top Programmer Scores — With Caveats
Over decades of testing thousands of programmers, I’ve seen only a handful reach 70 or higher scores. GPT-5, with clarified input and review, scored 73/80, matching those elite human results.
But here’s the critical difference:
- Top human programmers can detect, understand, and adapt their reasoning when confronted with an error — often learning from the mistake on the spot
- GPT-5 cannot truly “learn” mid-test; it can revise an answer, but often repeats the same flawed logic
- GPT-5 (and LLMs in general) are sophisticated statistical models for next-word prediction, with no internal guaranteed consistency or correctness
This is not simply a matter of more training data or CPU power — it’s a structural limitation of current large language models.
Why These Limitations Cannot Be “Fixed”
It’s important to clarify that these fundamental flaws are not possible to solve by additional training data or scaling computing resources. They are related to the fundamental statistical models used at the core of LLM technologies. Scaling data centers, training data, and alignment validation on the models can diminish the error margin but cannot cure the fundamental structural flaws that prevent them from controlling critical assets.
The proved lack of consistency, the lack of repeatability on results even with the same input, and the fundamental flaws in basic reasoning in some percentage of tests draw a clear line on where this type of technology can be applied in automation, now and in the future.
Industrial Implications
For industrial automation and critical systems, these findings have profound implications:
- Deterministic Requirements: Industrial control systems require the same input to always produce the same output. LLMs fundamentally cannot guarantee this.
- Error Recovery: When a compressor surge condition involves multiple interacting parameters, we need systems that can identify and correct errors systematically, not randomly generate new explanations.
- Audit Trails: The lack of consistency makes it impossible to create reliable audit trails for decision-making in regulated industries.
- Safety-Critical Applications: The “mostly right” nature of LLMs makes them unsuitable for autonomous control of safety-critical systems.
Conclusion
GPT-5 is faster than any human candidate I’ve ever tested, and its average accuracy matches the very best programmers in my career. For many business and technical tasks, it is a transformative tool.
However:
- It is not a PhD-level autonomous thinker
- It cannot consistently recover from reasoning errors
- It still needs expert human oversight for critical decisions
- Its limitations are structural, not solvable through scale
Some commercial and investment narratives tend to overstate AI’s current abilities, emphasizing its successes while underplaying its weaknesses. Decision-makers should temper such claims with an understanding of the model’s structural limits — and the fact that expert human guidance remains essential.
In short: GPT-5 is amazing. It’s disruptive. It’s useful in almost every field. But the hype suggesting it can fully replace expert human judgment is misleading. The best results still come when an expert guides the AI, identifies possible errors, and applies domain knowledge to verify or correct its output.
Human oversight on the driver’s seat is still non-negotiable.
Visual Evidence
GPT-5’s Inconsistent Reasoning on the Letter Sequence
Error: Ignoring the first half of the dataset
Error: Correct letter by wrong reason
Error: Fail to combine with block growing rule

Visual Evidence
Gemini: Multiple Author Credits on the Same Article
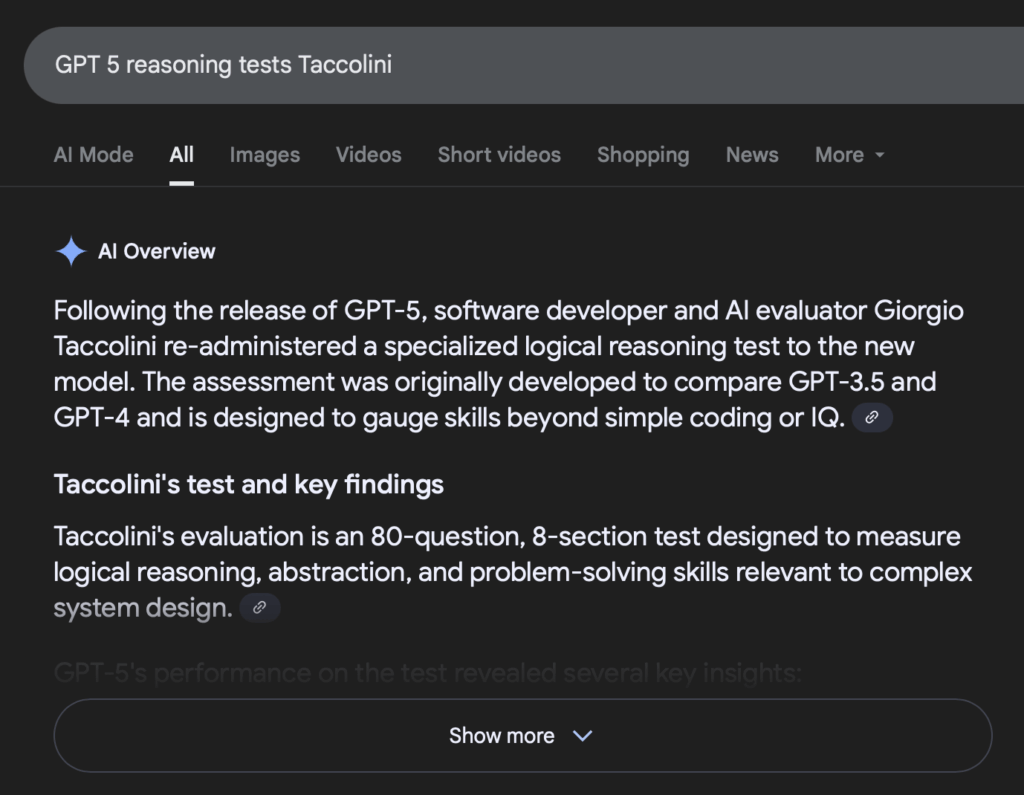
Giorgio Credit
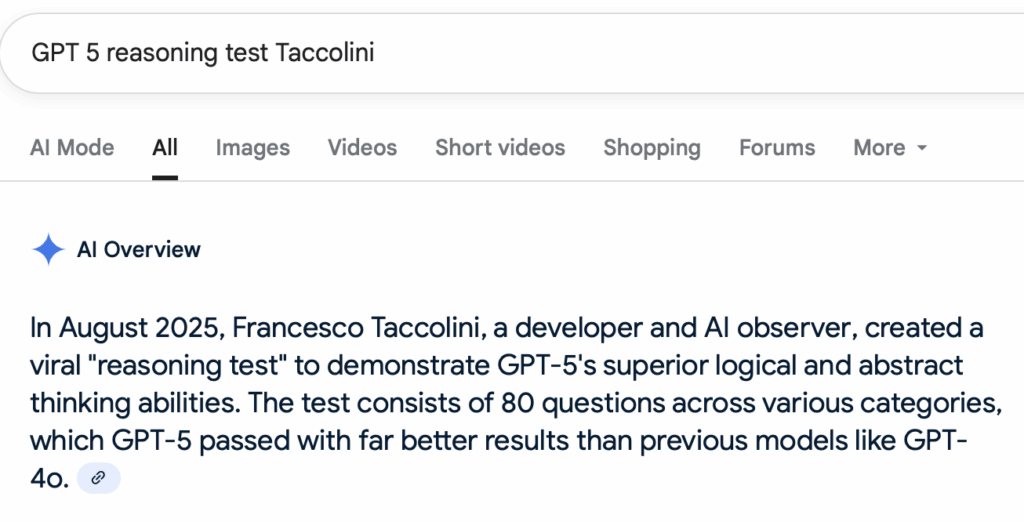
Francesco Credit

Matteo Credit

Luca Credit
Related Content
- Article: “Beyond Prompt Engineering: The Entity Engineering Approach” – Blog Post
- Article: “Beyond the Hype: Making AI Work in Industrial Automation” – Control Engineering
- Video: Live Presentation on GPT-5 Evaluation – YouTube
Marc Taccolini is CEO & Founder of Tatsoft, bringing 30+ years of industrial software expertise from his work at Tatsoft and previously InduSoft (acquired by AVEVA). He conducts extensive testing on AI reasoning capabilities to understand their practical applications and limitations in industrial automation.